Bienvenidos al Escritorio de Enrique. Antes de nada, si queréis descargaros en pdf el contenido de esta entrada podéis pinchar en este enlace post14. En el artículo de hoy vamos a tratar el concepto de función recursiva y veremos lo elegantes y útiles que son. Además, nos introduciremos en el mundo de los algoritmos y veremos qué quiere decir que un algoritmo es eficiente.
Imaginaos que para definir un concepto utilizais ese mismo concepto. Eso, diréis, está mal porque es la pescadilla que se muerde la cola. Y con razón. Pero si se hace con cuidado, podéis definir algún concepto matemático utilizando ese mismo concepto y tener una definición perfectamente rigurosa. Vamos a verlo.
Factorial
Quizás recuerdes del instituto números como este: 
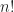



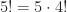
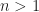

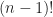

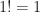
- Caso base:
- Caso recursivo: para todo
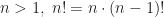
A esto se le llama recurrencia (y no recursión, que es una mala traducción). Si os fijáis, hemos definido factorial de un número como ese número multiplicado por el factorial del número precedente, utilizando el mismo concepto que queremos definir. La clave de todo esto es darnos cuenta de que necesitamos un caso base y observar que el tamaño del objeto al cual le estamos aplicando la definición es más pequeño que en el paso anterior. Tiene que ser así, porque si definiéramos factorial con el mismo caso base pero con el caso recursivo 
Por cierto, como añadido mencionaré que también se suele definir 
Más definiciones recursivas
En matemáticas, las definiciones recursivas son bastante comunes. Una de las más famosas es la de la sucesión de Fibonacci. Tal vez la recuerdes por guardar relación con la proporción áurea. La sucesión de Fibonacci le surgió a Leonardo de Pisa (Fibonacci) cuando estudiaba la reproducción en los conejos (obviamente sería un pasatiempo más que un estudio biológico, pues los conejos no se reproducen así). El problema (muy incestuoso) consiste en lo siguiente: al principio del mes 1 nace una pareja, A, de conejos. Al final del mes 1 se reproducen. Al final del mes 2 nace otra pareja de conejos, B, y la primera pareja, A, se vuelve a reproducir. Al final del mes 3 nace una pareja de conejos, C, y se reproducen las parejas A y B. Y así sucesivamente. En general, cada mes nace una pareja de conejos de cada pareja que se ha reproducido en el mes anterior, y cada una de estas parejas se reproduce en el mes siguiente. El problema consiste en saber cuántas parejas de conejos hay en cada mes. No vamos a detallar cómo llegamos a la solución, la famosa sucesión, pues en este artículo solo nos interesa su aspecto matemático. Si al número de parejas de conejos en el mes 
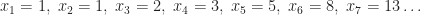


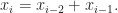
Pensemos un poco ahora en la eficiencia de un ordenador a la hora de hacer estos cálculos. La eficiencia de un ordenador consiste en la cantidad de tiempo y memoria que necesita para efectuar los cómputos de un algoritmo. En general, dado un problema (como por ejemplo este de calcular el término i-ésimo de la sucesión de Fibonacci), un algoritmo lo resuelve de manera más eficiente que otro algoritmo si la relación de tiempo-memoria que emplearía un ordenador (al implementar el algoritmo) es mejor que la del otro. El estudio de los problemas computacionales en función de la eficiencia de los algoritmos que los resolverían se llama teoría de la complejidad computacional, y es una de las ramas de las matemáticas y la informática de mayor relevancia en la actualidad. En próximos artículos trataré este tema.
Fijémonos en concreto en la cantidad de tiempo que necesitaría este algoritmo para obtener la solución. Busquemos, por ejemplo, el quinto término de la sucesión de Fibonacci y actuemos como lo haría un ordenador. El ordenador diría:
- Necesito calcular el término
, que se obtiene como
. Para ello necesito calcular
y
.
- Necesito calcular el término
.
- Necesito calcular
, pero ya sé que vale 1.
- Necesito calcular
, pero ya sé que vale 1.
- Así,
.
- Necesito calcular
- Necesito calcular el término
.
- Necesito calcular
- Necesito calcular el término
- Necesito calcular
- Necesito calcular
- Así,
- Necesito calcular
- Así,
.
- Necesito calcular
- Finalmente,
, que es el resultado esperado.
Ahora, para calcular el tiempo que hemos empleado habría que contabilizar las operaciones que hemos hecho; esto es lo que se suele contabilizar como tiempo de ejecución, el número de instrucciones básicas que contiene el algoritmo. No vamos a entrar en detalles, pero conforme se hace más grande el término de la sucesión de Fibonacci que queremos calcular, el tiempo de ejecución del algoritmo crece exponencialmente, y eso es muy malo. Como definición matemática del problema está muy bien, es limpio y elegante, pero a la hora de la verdad, es muy ineficiente. Hay variantes (recursivas también), en las que tampoco vamos a detenernos, que permiten calcular esto de manera mucho más rápida. La idea sería, como habréis podido deducir en el proceso anterior, guardar en alguna variable auxiliar los valores que ya hemos calculado. En el ejemplo anterior, si tuviéramos una variable 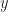
Como habréis comprobado, las funciones recursivas son uno de los núcleos de la programación. Los ejemplos que hemos presentado son bastante tontos pero muy ilustrativos tanto para ver qué significa recurrencia como para saber qué es la complejidad computacional.
Espero que os haya gustado. Si es así, dejádmelo en los comentarios y compartidlo con familiares, amigos y vecinos del barrio. ¡Hasta la próxima!
